{kind=link}
This is a talk that was given for Consilium Scientific today May 18 at the invitation of Leeza Osipenko. Consilium are doing more than anyone to raise questions about the quality of the evidence we have in medicine – in particular around controlled trials. They have had some fabulous contributions in recent months – all of which can be acess on their website. This Lecture by me came with a Question and Answer session that had its cut and thrust moment.
As usual with these lectures Bill James and I also recorded If God Doesn’t Play Dice, Should Doctors in a version that I think works very well.
Einstein
Einstein famously said that God does not play dice – with the universe. In France, in 1654, gambling with dice gave rise to probability theory, which led to what we now call medical statistics. 75 years ago doctors recruited medical statistics in the form of Randomized Controlled Trials (RCTs) to give them confidence when they Roll the Dice on the Drugs they give us.
How confident should we be?
{kind=link}
Slide 2: Fifty years after the first RCT, Don Schell, a tough oilman from Wyoming, was put on Paroxetine for a minor sleep problem. Forty-eight hours later he shot his wife, his daughter and grand-daughter and then himself. His surviving son-in-law took a lawsuit against GlaxoSmithKline (GSK) – Tobin v SmithKline.
In the Tobin case, Ian Hudson, Chief Safety Officer of GSK was asked – Can SSRIs cause suicide. He says GSK practice EBM which means they base their views on randomized controlled trials (RCTs) – which use probability to find the truth.
A jury of 12 people, with no background in healthcare, dismissed Hudson’s EBM in favor of Evident Based Medicine. Their diagnosis was it was obvious paroxetine caused this and GSK were guilty of negligence.
Hudson’s view, however, remains ensconced at the top of Britain’s drugs regulator, of which he was later the Chief Executive Officer – as well as top of FDA, EMA, and other regulators.
{kind=link}
Slide 3: Hudson’s views originate 70 years earlier in the work of a strange man – Ronnie Fisher. Here you see Fisher smoking a pipe. He dismissed the later link between smoking and lung cancer. Evidence was not Fisher’s strong point.
Fisher was not a doctor and never ran an RCT. Controlled trials and randomization were there before him but his book the Design of Experiments turbocharged them.
Fisher was trying to characterize expert knowledge. Experts know the right answer – like parachutes work. If we set up two groups, one with parachutes and the other not, we would expect those wearing parachutes to live and those not to die.
Chance was really the only thing that could get in the way of the expert being right – perhaps a strong wind lands a person in a snow covered tree. Chance could be assigned a statistically significant value. If 1 in 20 of those without parachutes lived, we wouldn’t say the expert didn’t know what he was talking about.
There might be other trivial things – someone with webbed feet might behave differently when falling, and randomization can control for any trivial unknown unknowns like this. Somehow Fisher’s book transformed randomization into something semi-mystical – that would help us overcome ignorance – but randomization can’t control for ignorance.
{kind=link}
Slide 4: Fisher’s expert is a Robin Hood who 19 times out of 20 can split a prior arrow lodged in the Bull. Expertise is precise, accurate and Real World.
{kind=link}
Slide 5: The RCTs done to license drugs, especially antidepressants, look like this rather than like Robin Hood. A mismatch on this scale indicates we are not dealing with expertise.
{kind=link}
Slide 6: Tony Hill ran the first medical RCT in 1947 giving streptomycin for tuberculosis. Hill later showed smoking caused lung cancer. He had no time for Fisher. He knew doctors were not experts. His trial was not a demonstration of expertise. He used randomization as a method of fair allocation – not to manage mystical confounders.
Hill’s RCT found out less about streptomycin than a prior non-randomized trial in the Mayo Clinic, which showed it can cause deafness and tolerance develops rapidly.
{kind=link}
Slide 7: In a 1965 lecture, Hill took stock of RCTs. He mentions that it is interesting that the people most heavily promoting RCTs are pharmaceutical companies.
He didn’t think trials had to be randomized. He thought double-blinds could get in the way of doctors evaluating a drug. He believed in Evident Based rather than Evidence Based Medicine.
Hill said we needed RCTs in 1950 to work out if anything worked. By 1960, we had lots of drugs that worked, none discovered by RCTs, and the need was to find out which drug worked best. This is not something RCTs can do – there is no such thing as a best drug.
He also said that RCTs produce average effects, which are not much good for telling a doctor what to do for the patient in front of them.
Here in this quote he is saying RCTs can help evaluate one thing a drug does which means they are not a good way to evaluate a drug overall. All RCTs generate ignorance but we can bring good out of this harm if we remember that. Hill never saw RCTs replacing clinical judgement.
{kind=link}
Slide 8: This 1960 RCT run by Louis Lasagna makes Hill’s point. Thalidomide has therapeutic efficacy as a sleeping pill but this trial missed the SSRI-like sexual dysfunction, suicidality, agitation, nausea and peripheral neuropathy it causes.
Two years later, Lasagna was responsible for incorporating RCTs into the 1962 FDA Act – in order to minimize the chance of another thalidomide. By doing this, he was, more than anyone else, the man who got us using RCTs. The mechanism he put in place to stop thalidomide happening again was one it sailed through.
Other regulations aim at safety – whether for planes, cars, food or investment, bu the 1962 regulations uniquely stressed efficacy and in so doing badly compromised safety.
{kind=link}
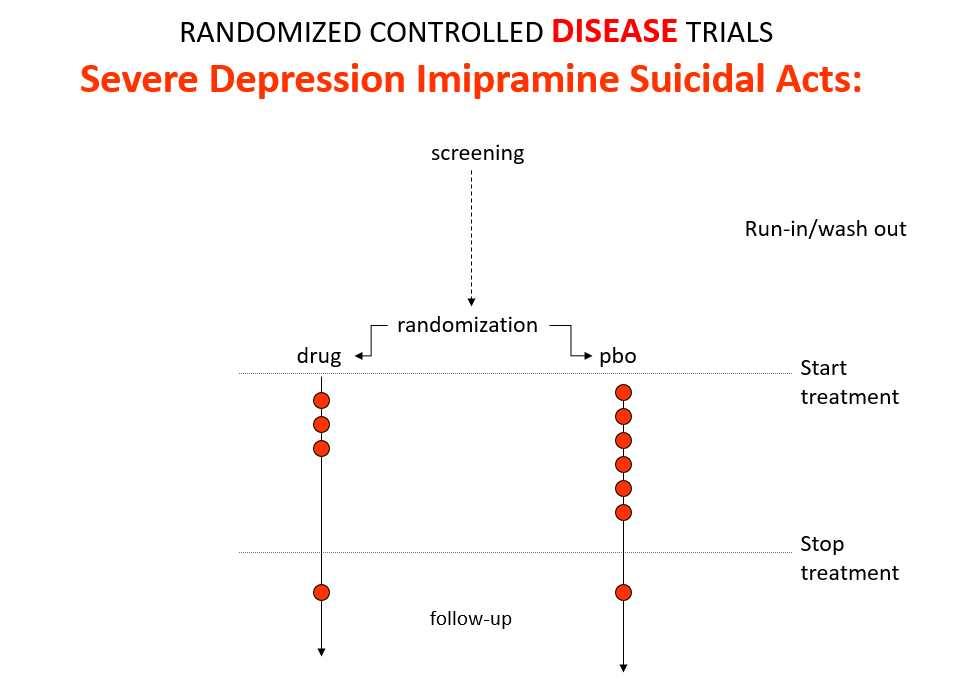
Slide 9: The 1950s gave us better antihypertensives, hypoglycemics, antibiotics and psychotropic drugs than we have ever had – all without RCT input.
Imipramine, the first antidepressant, is much stronger than SSRIs. It can treat melancholia –SSRIs can’t. Melancholia comes with an 80-fold increased risk of suicide.
In an RCT of imipramine versus placebo in melancholia, we would expect the red dots showing suicide attempts to be less on imipramine even though it can cause suicide because it treats this high risk condition. This RCT would look like evidence imipramine cannot cause suicide.
Imipramine was launched in 1958. At a meeting in 1959, experts noted that while it was a wonderful treatment it made some people suicidal. Stop the drug and the suicidality clears. Re-introduce it and suicidality comes back. This was Evident Based Medicine.
{kind=link}
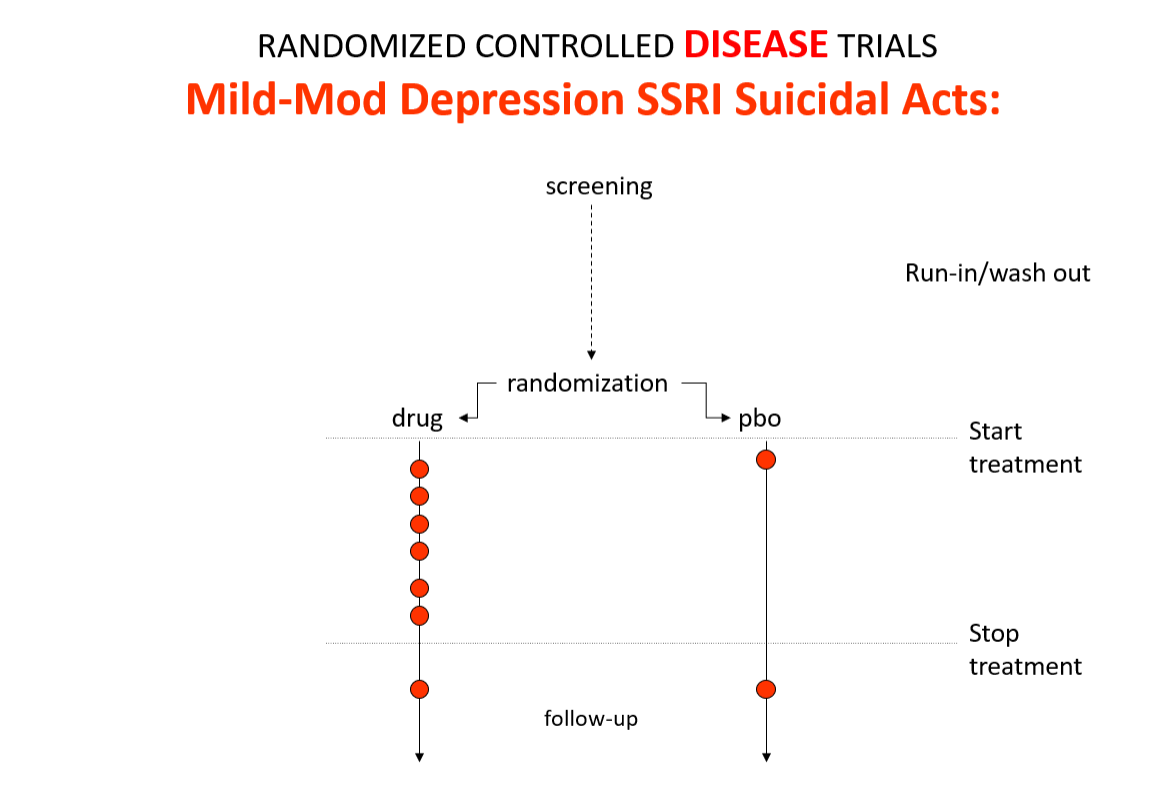
Slide 10: In the mild depression trials that brought the SSRIs to market – we see an increase of suicidal events compared to placebo in people at little or no risk of suicide.
{kind=link}
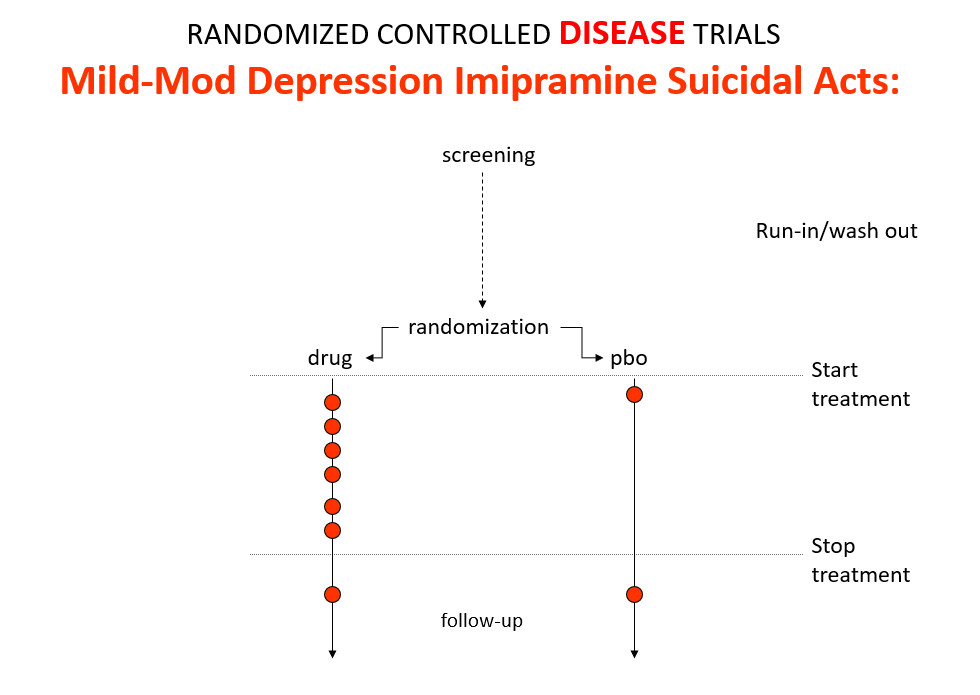
Slide 11: Used as a comparator in these trials imipramine now too causes suicides.
The diametrically opposite RCT outcomes for imipramine stem from the fact these are Treatment Trials not Drug Trials. If the condition and treatment produce superficially similar effects, RCTs can confound us. This is true for most medical conditions and their treatments.
If you want to see what a drug does – you should do a Drug Trial.
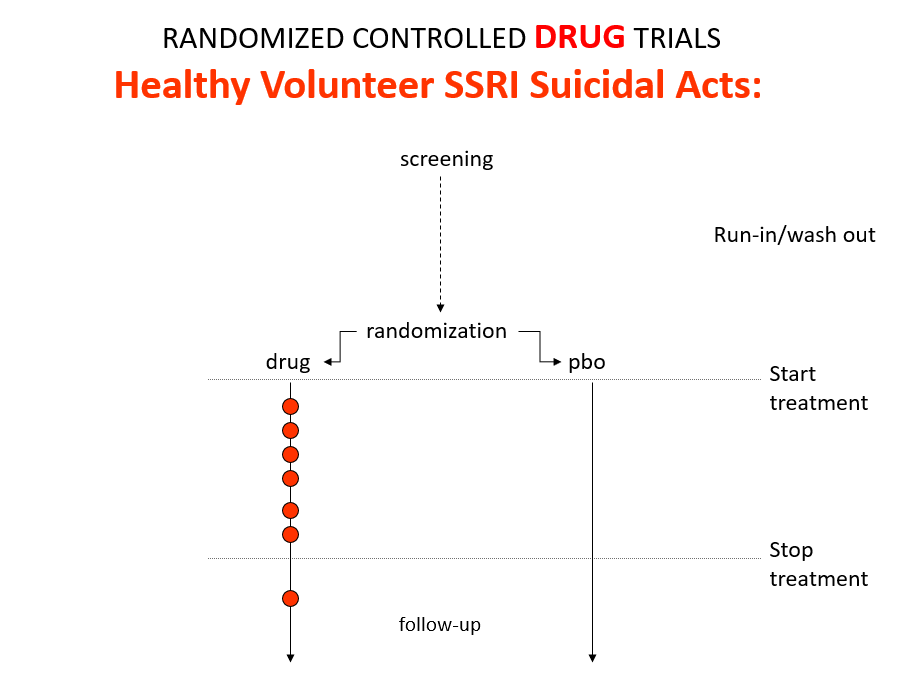{kind=link}
Slide 12: Here is what a Drug Trial looks like. In healthy volunteer studies in the 1980s, companies found SSRIs made volunteers suicidal, dependent and sexually dysfunctional. These Drug Trials enabled companies to engineer Treatment Trials to hide these problems.
{kind=link}
Slide 13: There are more dead bodies on SSRIs than on placebo in trials, yet the RCTs show the drugs work. This is because working is measured on a surrogate outcome. For antidepressants it’s the Hamilton Scale for Depression. Fifteen years after its creation, Max Hamilton commented that this scale standardizes clinical interviews which can be good and bad.
{kind=link}
Slide 14: In trials, the Hamilton scale has suicide, appetite, sleep, anxiety and sex items on all of which the illness or the drug may produce effects. If Leeza is in an RCT and I ask her if she has been suicidal in the last week, if she says yes she tried to kill herself, I would score a 4. But if I figured this was caused by the drug I would score a Zero.
But trials eliminate judgement. Introduce judgement and one knows what the results mean. Trials have become just the opposite to what Tony Hill intended.
{kind=link}
Slide 15: In addition to randomization, Fisher put Statistical Significance on the map. By 1980 every leading medical statistician was saying we need to get rid of statistical significance in favor of Confidence Intervals.
This image is from the James Webb telescope. Confidence Intervals were introduced by Gauss in 1810 to solve a telescope problem. Because of measurement error, telescopes often failed to establish if there was one or two stars in a location. As measurement errors should distribute normally, confidence intervals could help distinguish individual stars.
{kind=link}
Slide 16: Confidence intervals rushed into therapeutics in the mid-1980s. Leading medical statisticians argued they were more appropriate than significance testing. They are more appropriate for measurement error but is this what we have in Treatment Trials?
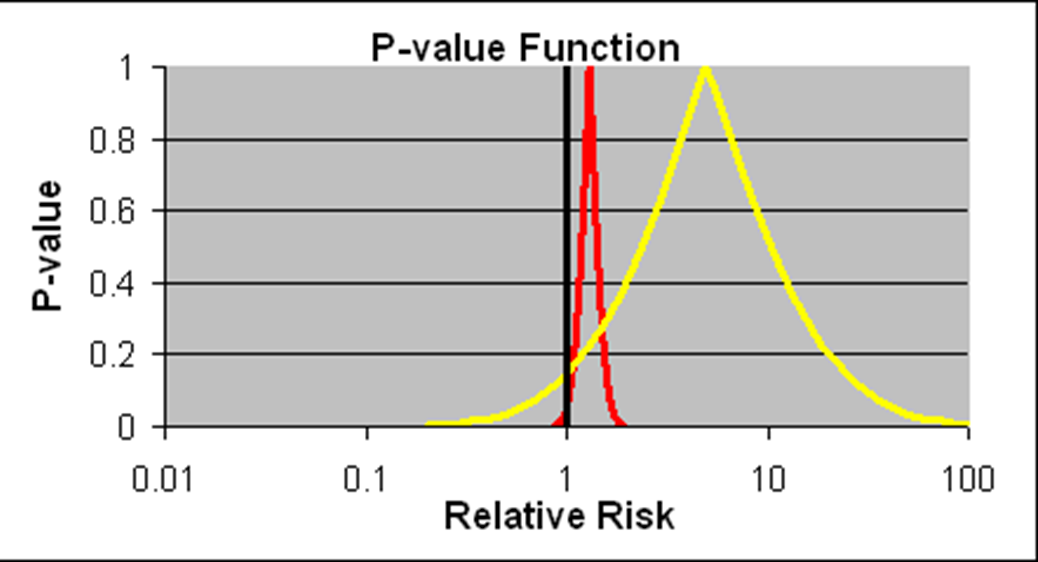{kind=link}
Slide 17: Confidence intervals allow us to estimate the size of an effect and the precision with which it is known. The details on the likelihood of the Red Drug killing you here are more precise than for the Yellow Drug. The best estimate of the lethality of the Yellow Drug however is greater. The standard view is that if we increase the size of the Yellow Drug Trial, we will have greater precision and know better what the risks are. This is wrong, as you will see.
If you are forced to take one of these drugs, as things stand now, Ian Hudson, and FDA will say the only dangerous drug here is the Red One. This is because more than 95% of the data, more than 19 out of 20 data points, lie to the right of the line through 1.0. This is exactly what medical statisticians say is wrong.
I would take the Red drug, because these confidence intervals are not managing measurement error and we don’t know what they mean when they are not representing measurement error.
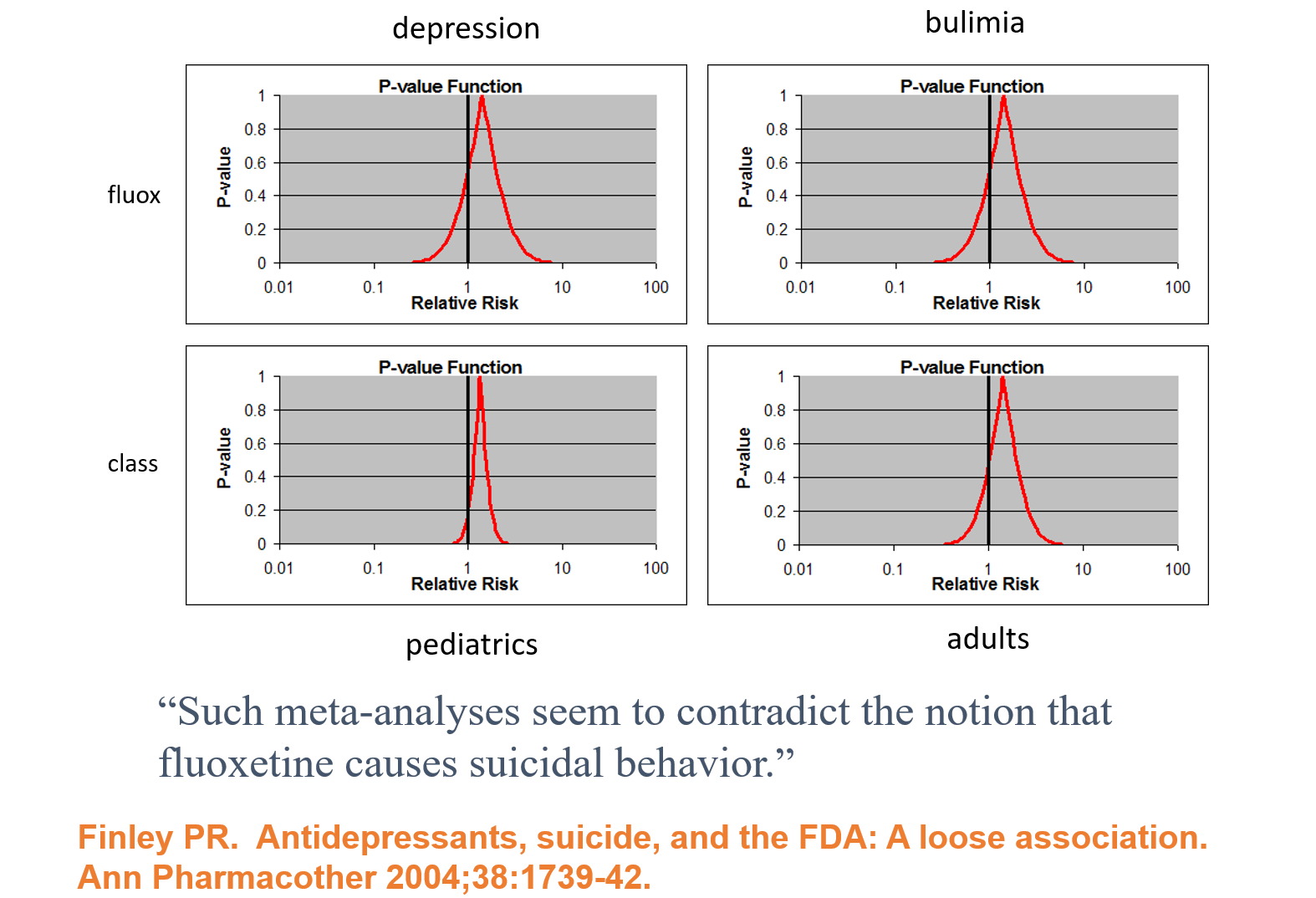{kind=link}
Slide 18: In 1991, facing claims Prozac caused suicide, Lilly analysed their RCTs and spun the Confidence Intervals here as evidence Prozac does not cause suicide. This is Ian Hudson thinking – there is no problem as nothing is statistically significant.
Sander Greenland and leading medical statisticians say you need to view these as compatibility intervals rather than confidence intervals. All these curves show a compatibility with Prozac causing suicide and the consistent excess of suicidal events in all groups points strongly to a problem.
The bigger point is that for 100 years statisticians have been telling us we cannot assume that statistical data bears any relationship to the real world – we have to establish it.
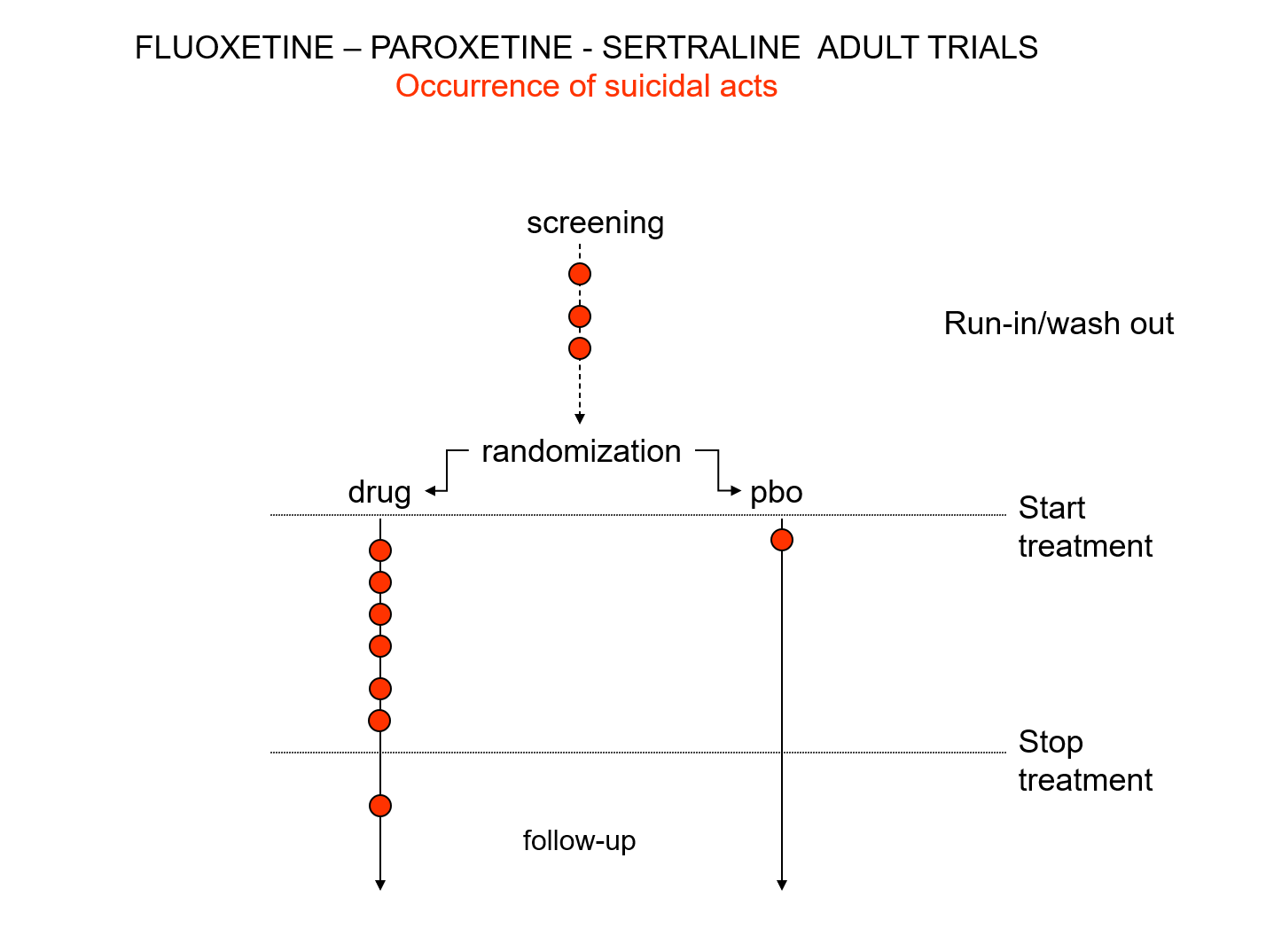{kind=link}
Slide 19: Here is a representation of suicidal events from the trials bringing Prozac, Seroxat and Zoloft to market around 1990. Note the events under screening. There is a 2 week washout period before a trial starts where people are taken off prior drugs before being randomized. This phase of a trial is dangerous – people are in withdrawal and may become suicidal.
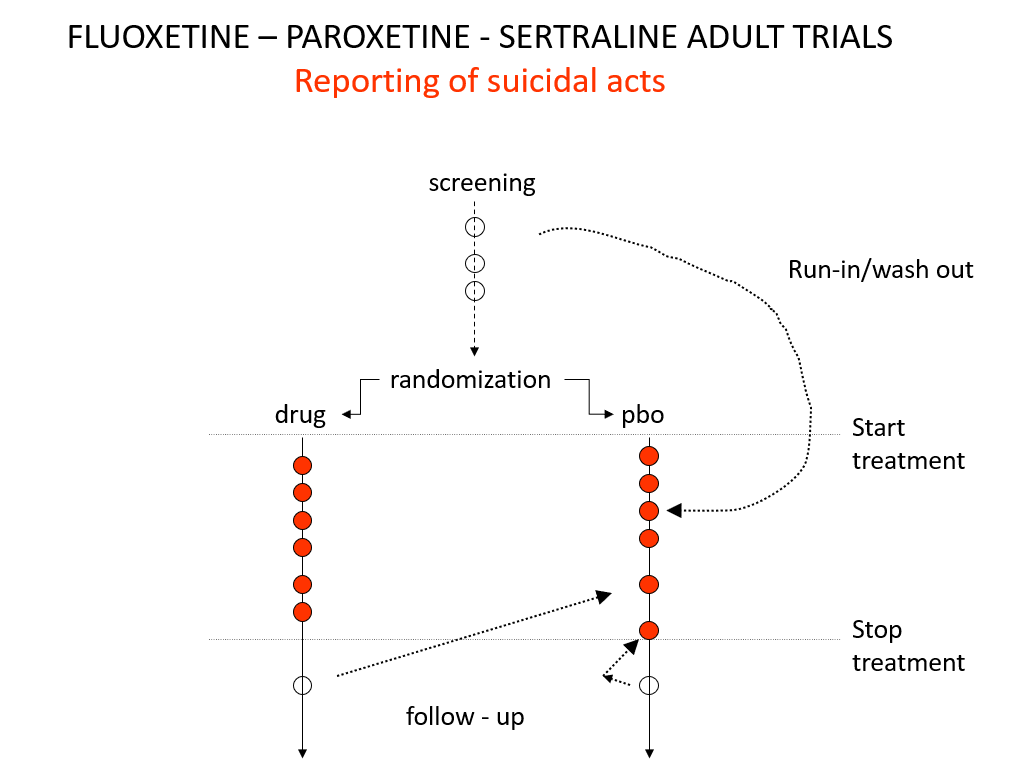{kind=link}
Slide 20: When submitting the data to FDA, the companies moved events as you see here – arguing people in the run in phase were on nothing which is equivalent to being on placebo. There were other maneuvers at the end of the trials as ou see here.
Even with these maneuvers, there was an excess of suicidal events on SSRIs but the 95% confidence interval was no longer to the right of 1.0. Why do this? Because regulators and companies need a Stop-Go mechanism and statistical significance provides this. But doctors don’t need an external Stop-Go mechanism to replace their clinical..